Share
As deep learning models continue to grow in size and complexity, efficiently training these massive networks has become a significant challenge. Traditional parallelism strategies like data parallelism and model parallelism have been instrumental but come with their own limitations. Enter sequence parallelism—a novel approach that addresses some of these constraints, offering a new avenue for optimizing large-scale model training.
Data Parallelism involves splitting the input batched data across multiple GPUs. Each processor works independently on its portion of the data using the same model parameters. After computation, gradients are aggregated to update the model synchronously. This method is relatively straightforward and scales well with the number of processors. However, it is not designed for models that exceed the memory capacity of a single GPU.
Model Parallelism, on the other hand, partitions the model weights itself across multiple GPUs. Different layers or components of the model are allocated to different processors. While this allows for training larger models, it introduces significant communication overhead between GPUs, potentially leading to inefficiencies and slower training times.
Traditional strategies like data parallelism and model parallelism distribute workloads across multiple GPUs but often encounter limitations when dealing with very large models or long input sequences. In Sequence parallelism, the input sequence is split across multiple GPUs, allowing for efficient training of large models like transformers. Utilizing the scatter and gather design patterns, presents a novel solution by dividing input sequences across GPUs, enabling efficient training without overwhelming memory constraints.
How Sequence Parallelism Works
In sequence parallelism, an input sequence is divided into segments, each assigned to a different GPU. For instance, if you have a sequence of 1,000 tokens and four GPUs, each GPU processes 250 tokens. This approach keeps GPUs busy and optimizes training in the following way:
Local Computations
Each GPU independently computes the embeddings and initial layers for its segment of the sequence. This ensures that all GPUs are actively processing data without waiting on others, maximizing parallel efficiency.
Attention Mechanism with Communication
Transformers and similar models rely on attention mechanisms that require access to the entire sequence. To handle this:
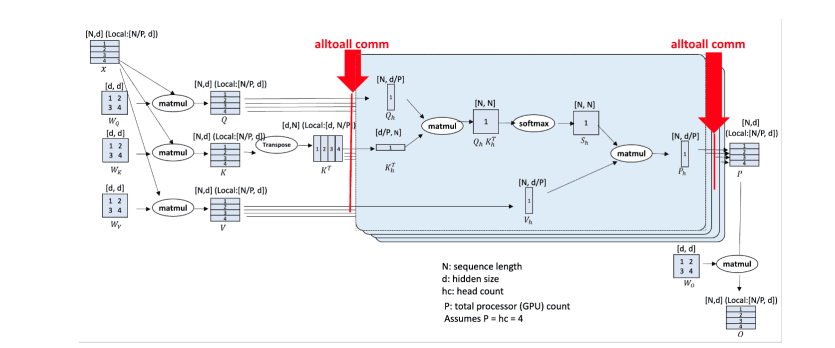
Figure 2. DeepSpeed sequence parallelism (DeepSpeed-Ulysses) design
Figure 2 shows the core design of DeepSpeed-Ulysses paper. As with the known transformer architecture, the design consists of input sequences NNN partitioned across PPP available devices. Each local N/PN/PN/P partition is projected into queries (Q), keys (K), and values (V) embeddings. Next, the QKV embeddings are gathered into global QKV through highly optimized all-to-all collectives between the participating compute devices. Following the all-to-all collective is the attention computation per head, expressed in the form:
Outputcontext = Softmax((QKT )/ p(d))V
With the complete keys and values, each GPU computes attention scores for its queries against the entire sequence. This computation is intensive and fully utilizes the GPUs' capabilities. By employing the gather pattern, GPUs collect the necessary information to perform these computations, ensuring that each token can attend to every other token in the sequence.
GPUs update their token representations using the attention outputs and proceed to process subsequent layers like feed-forward networks. This continuous computation ensures GPUs remain occupied, maintaining high efficiency throughout the training process.
After certain layers, GPUs synchronize to maintain model consistency. Efficient communication protocols minimize idle time during these synchronization phases, ensuring that the overall training process remains streamlined.
During training, each GPU computes gradients for its segment. Necessary gradients are exchanged between GPUs to update shared model parameters, keeping all GPUs engaged in both computation and communication. This collaboration ensures that the model converges correctly while maximizing resource utilization.
By overlapping computation with communication, sequence parallelism maximizes GPU utilization. GPUs are either processing data or communicating essential information, significantly reducing idle times. This method allows for training larger models with longer sequences without exceeding individual GPU memory limits, effectively scaling deep learning models.
Projects like NVIDIA's Megatron-LM and Microsoft's DeepSpeed have successfully implemented sequence parallelism using scatter and gather patterns:
By employing the scatter and gather design patterns, sequence parallelism offers several benefits:
Incorporate AI ML into your workflows to boost efficiency, accuracy, and productivity. Discover our artificial intelligence services.
View All
Breaking down Kolmogorov-Arnold Networks and understanding how they offer a fresh perspective on neural network architecture design.
How register tokens help Vision Transformers reduce background noise artifacts and improve feature map quality.
A hands-on tutorial on using Physics-Informed Neural Networks to model the classic lid-driven cavity flow problem.
© Copyright Fast Code AI 2026. All Rights Reserved