Share
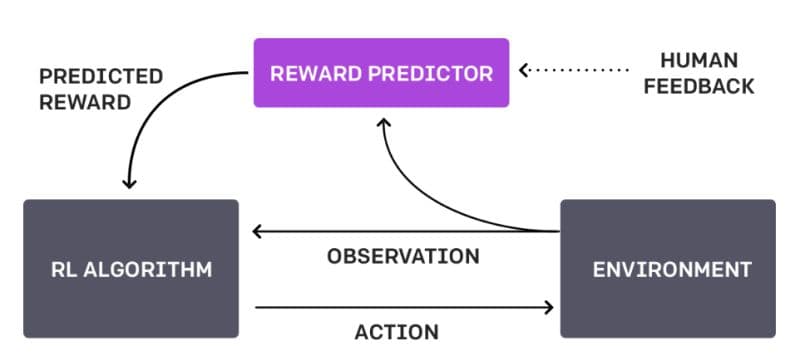
Reinforcement Learning from Human Feedback (RLHF), is a transformative technique that harnesses human feedback to steer and refine machine learning models. It is a sophisticated technique where models undergo fine-tuning using human feedback as a direct reward signal. The process begins with data collection, where the model generates responses that human reviewers subsequently rank. Using this collected data, a reward model is constructed. This model ranks the machine's outputs based on human preferences. The model is then fine-tuned using Proximal Policy Optimization (PPO), an advanced reinforcement learning algorithm. The reward model serves as a guide during this optimization. This entire process of data collection, reward modelling, and PPO-based fine-tuning is iteratively performed, ensuring continuous refinement of the model's behavior.
It is an indispensable mechanism in the realm of Language Learning Models (LLMs), acting as a pivotal steering agent in content generation. At its core, RLHF employs a sophisticated blend of human feedback and advanced reinforcement learning algorithms to calibrate and fine-tune LLM outputs. By leveraging real-time evaluations from human reviewers, RLHF systematically guides the model to align its responses with predefined guidelines, human values, and ethical standards. This iterative feedback loop, combined with techniques such as Proximal Policy Optimization (PPO) for model optimization, ensures that LLMs not only produce high-quality content but also avoid generating outputs that could be biased, misleading, or potentially harmful. Through RLHF, LLMs are equipped with a dynamic and adaptive framework, enabling them to navigate the intricate nuances of human language with precision, accuracy, and ethical integrity.
While Reinforcement Learning from Human Feedback (RLHF) provides a robust framework for guiding Language Learning Models (LLMs) in content generation, it's not impervious to challenges. Specifically crafted prompts, designed with intricate knowledge of the model's architecture and training data, can exploit latent vulnerabilities, leading the model to produce unintended or undesired outputs. Additionally, advanced adversarial techniques, which introduce carefully calibrated noise or perturbations to the input, can mislead the model into deviating from its expected behavior. These techniques, often rooted in deep understanding of neural network behaviors, can effectively bypass the safeguards put in place by RLHF, highlighting the perpetual cat-and-mouse game between model developers and adversarial actors in the AI landscape.
Incorporate AI ML into your workflows to boost efficiency, accuracy, and productivity. Discover our artificial intelligence services.
View All
How federated learning enables collaborative model training while keeping sensitive data private and secure.
Why open-source AI is critical for preventing monopolization and ensuring equitable access to artificial intelligence.
A practical approach to tackling complex engineering problems by breaking them down into simpler, manageable components.
© Copyright Fast Code AI 2026. All Rights Reserved